-
Why another archiver?Archiving millions of PVS requires a few additional features. In addition to focusing on the EPICS side of the equation, we also need to address the various IT aspects like flexibility, scriptability, policy enforcement etc. A integrated multi-head, multi-stage solution was called for; hence the appliance.
-
What are the various configuration items?The various aspects of configuration are separated logically.
In addition to this, the configuration for each PV is stored in theEnvironment variable Description Default ARCHAPPL_APPLIANCESThis is mandatory and points to a file containing the list of appliances in this cluster. This must be identical across all members in the cluster. appliances.xmlARCHAPPL_POLICIESThis contains the full path name of your policies file. The policies file is a python script that controls the parameters for archiving. policies.pyinWEB/classesARCHAPPL_PROPERTIES_FILENAMEThis contains the full path name of archappl.propertiesfile. Thearchappl.propertiesis the misc bucket for configuration and is a Java properties file with various name/value pairs.archappl.propertiesinWEB/classesARCHAPPL_MYIDENTITYThis contains the identity of this appliance; of course, this is different for each appliance. The appliance identity needs to match the identity as defined in the appliances.xmlgetCanonicalHostName()inInetAddress.getLocalHost()PVTypeInfotable in the MySQL configuration database specific to each appliance. The connection pool for the database is typically configured in Tomcat'sconf/context.xml. -
Where are the logs?Most deployment have four tomcat containers per appliance - one each for the engine, ETL, retrieval and mgmt components. All the logs typically are sent to
arch.logor similar files in theCATALINA_HOME/logsof these containers. Log levels are typically controlled using alog4j.propertiesfile in theTOMCAT_HOME/libfolder of these containers. -
What's the difference between SCAN and MONITOR?These are minor variations of the similar concepts in the ChannelArchiver and other archivers. Both SCAN and MONITOR use camonitors.
- For MONITOR, we estimate the number of samples based the PV's sampling period, allocate a buffer to accommodate this many samples and fill it up.
The buffer's capacity is computed using something like so (see
ArchiveEngine.java:addChannel)int buffer_capacity = ((int) Math.round(Math.max((write_period/pvSamplingPeriod)*sampleBufferCapacityAdjustment, 1.0))) + 1;- pvSamplingPeriod is the sampling_period from the PV's PVTypeInfo
- write_period is the engine's write period from archappl.properties ( where it's called secondsToBuffer ) ; this defaults to 10 seconds.
- sampleBufferCapacityAdjustment is a system-wide adjustment for the buffer side and is set in archappl.properties.
write_periodis 10 seconds, and thepvSamplingPeriodis 1 second, we would allocate10/1 + 1 = 11samples for the defaultsampleBufferCapacityAdjustment. Thus, in the case where the PV is changing at a rate greater than 1Hz, you should expect 11 samples, a gap where we run out of space and throw away samples, then 11 samples when we switch buffers and so on. For example, here's a 10Hz PV being MONITOR'ed at 1 second.Nov/22/2019 08:30:06 -08:00 -0.6954973468157408 0 0 717169462 ... Buffer switch drop samples here Nov/22/2019 08:30:15 -08:00 0.13051475393574385 0 0 717195856 Nov/22/2019 08:30:15 -08:00 0.1404225266840449 0 0 816931850 Nov/22/2019 08:30:15 -08:00 0.15031625729669593 0 0 917194635 Nov/22/2019 08:30:16 -08:00 0.1601949564088804 0 0 17161946 Nov/22/2019 08:30:16 -08:00 0.17005763615891936 0 0 117100329 Nov/22/2019 08:30:16 -08:00 0.17990331028705667 0 0 217167979 Nov/22/2019 08:30:16 -08:00 0.1897309942340842 0 0 317064449 Nov/22/2019 08:30:16 -08:00 0.19953970523979697 0 0 416941153 Nov/22/2019 08:30:16 -08:00 0.2093284624412683 0 0 516970909 Nov/22/2019 08:30:16 -08:00 0.21909628697093528 0 0 617021076 Nov/22/2019 08:30:16 -08:00 0.22884220205448483 0 0 717085134 .... Buffer switch drop samples here Nov/22/2019 08:30:25 -08:00 0.9047907734809058 1 4 717192286 -
For SCAN, the engine updates one slot/variable at whatever rate is sent from the IOC.
And then a separate thread periodically picks the value of this one slot/variable every
pvSamplingPeriodseconds and writes it out to the buffers. Here's a 10Hz PV being SCAN'ed at 1 second.Oct/14/2022 15:39:09 -07:00 -0.082646851757071 0 0 104167026 Oct/14/2022 15:39:10 -07:00 0.017257914497692813 0 0 104108497 Oct/14/2022 15:39:11 -07:00 0.11699024537550369 0 0 104114128 Oct/14/2022 15:39:12 -07:00 0.21555364839335575 0 0 104165581 Oct/14/2022 15:39:13 -07:00 0.31196331060902366 0 0 104159716 Oct/14/2022 15:39:14 -07:00 0.40525593854644537 0 0 104164170 Oct/14/2022 15:39:15 -07:00 0.4944993831057127 0 0 104162904 Oct/14/2022 15:39:16 -07:00 0.5788019532887497 1 4 104161185 Oct/14/2022 15:39:17 -07:00 0.657321325681012 1 4 104158642 Oct/14/2022 15:39:18 -07:00 0.7292729606686096 1 4 104169748
- For MONITOR, we estimate the number of samples based the PV's sampling period, allocate a buffer to accommodate this many samples and fill it up.
The buffer's capacity is computed using something like so (see
-
How are timezones handled?EPICS IOC's use UTC as their timezone. The EPICS Archiver Appliance also uses UTC for data storage and retrieval; that is, data is received, stored and retrieved as UTC timestamps. Conversion to local time zones are to be done at the client/viewer. The various viewers handle the transition into and out of daylight savings appropriately. For example, in this case, there are two
01:00blocks on the x-axis to handle the extra hour inserted when daylight savings comes to an end at 01:00 on Nov/1/2015.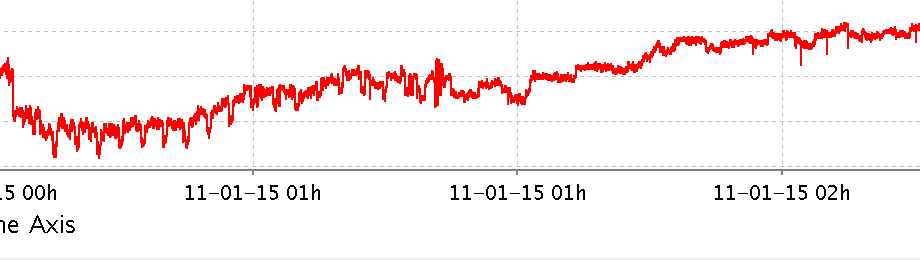
-
How are EPICS aliases supported?
When adding a PV with an alias to the archiver, the archiver uses the
NAME/NAME$fields of the PV to determine the real name. The PV is then archived under the real name and an entry is added to thePVAliasestable with the alias name. Data retrieval and management are then supported under both names.For aliased PV's, the PVDetails of the PV should an a line indicating that this PV is an alias for the real PV.
Also, in the mgmt webapp's arch.log, there should be an entry indicating this like so Aborting archive request for pv ABC:DEF:ALIAS Reason: Aborting this pv ABC:DEF:ALIAS (which is an alias) and using the real name ABC:DEF:REAL instead.